
人間同士の文字によるコミュニケーションでは、同じ文字表現でも受け取られ方が異なり、時には誤解が生じることもあります。例えば、グループ内で遊びに行こうというときに、「あなたは何で来るの?」と書いてしまうと、「来てほしくないのに来るの?」と解釈されるか「どんな交通手段で来るの?」と解釈されるか、それは読み手次第であり、書き手の意図に合った情報が伝えられるかどうかわかりません。実は、コンピューターの中でもこのような「同じ文字でも受け取られ方が異なり正しく伝わらない」という問題が起きることがあります。少し大まかな説明になりますが、今回は、そのような話を紹介させてください。
現代社会で一般的に用いられているのは、0~9の順に数字を使いその次に1桁上がるという10進数です。これに対して、コンピューターではデータを0と1の2進数で表現しています。例えば10進数の「84」であれば2進数では「01010100」となります。0と1だけでは桁数が多くなってしまうことから、人が扱う際には8進数や16進数に置き換えて表現することもあります。「01010100」であれば、8進数(0~7で表現)なら「124」、16進数(0~9A~Fで表現)なら「54」となり短い桁数で表現できるのです。16進数はあまり身近で見かけることはないかもしれませんが、ネットワークに接続する際に使用されるIPv6アドレスやホームページを作る際に色の指定(例えば1E50A2は瑠璃色)として見かけた人もいるかもしれません。
コンピューターで扱う「文字」もデータなので同様です。2進数で表されて、文字ごとに個別の数値が割り当てられています。このような仕組みは文字コードと呼ばれています。つまり、文字コードは、どのような文字集合をどのような数値で表すのかの対応表のようなものになります。例えば半角の英数字・記号の文字コードであるASCIIコードでは、半角の「T」は「01010100(16進数では54)」で表されます。
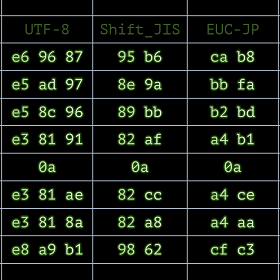
ところで日本語は、ひらがなやカタカナや漢字も使うため、ASCIIコードだけでは表現できません。そこでこれらの文字を含む文字集合(JIS X 0208)を数値に符号化することになりました。具体的な符号化方式には ISO-2022-JP、Shift_JIS、EUC-JPなどがあり、よく使用されてきました。文字集合が同じでも、符号化の方法が異なるということは、対応する数値が異なることを意味します。例えば、「密」という字では、ISO-2022-JP、Shift_JIS、EUC-JPでは、それぞれ16進数表記だと「1B24424C29」「96A7」「CCA9」となります。このように異なる数値が割り当てられているため、例えば「96A7」として文字データがあっても、必ずしも「密」として解釈されるかどうかはわからないのです。この例では、データを読む側が「これはShift_JISにより符号化されたデータだ!」と受け取ってくれない限り、元の「密」に戻すことができず、まったく別の文字として解釈されてしまいます。
このような問題を抱えつつ、コンピューターで文字を扱う際に、ほとんどが正しく表示されているのは、多くの場合、データの読み手であるアプリケーション側で文字コードを判定し、適切に復号化しているからです。しかし人間同士のコミュニケーションでは、読み手が適切に意図をくみ取ってくれるかわかりませんから、誤解を与えないように書き手側が普段から気をつけたいものです。
今回のお話は、少し古くから使われている日本語に対応した文字コードで説明させていただきましたが、現在では、日本語だけでなく世界中の文字や絵文字までも表現することができるUnicodeが広く使われてきているように感じます。おそらくコンピューターで使用される文字コードは今後、Unicodeに統一されていくであろうと個人的には思います。しかし、Unicodeも符号化方式がUTF-8やUTF-16など1種類に統一されているわけではありません。どのような違いがあるのか興味を持った方はぜひ調べてみてください。